На основе спектрально-статистического подхода [3, 4] к выявлению достоверной и значимой
неоднородности в последовательностях ДНК была создана технология поиска сильно
размытых тандемных повторов в геноме. Теоретический предельный уровень
дивергенции копий паттерна в находимых
тандемных повторах составляет 50%. Созданный комплекс программ универсален, он одинаково хорошо работает как с микро- и
минисателлитами с длиной паттерна от 2 до 100, так и периодичностями с длиной паттерна в несколько тысяч
нуклеотидов (н.п.) [1, 2].
Поскольку с алгоритмической точки зрения выявление скрытых периодичностей является очень трудной задачей, если истинная длина
периода a priori неизвестна, то для поиска сильно размытой периодичности (максимальный уровень дивергенции 50%) был
выбран метод поиска высоко значимой (на уровне α = 10-6) неоднородности
[4]. Для подтверждения значимости размытого тандемного повтора, содержащего небольшое
количество копий (случай недостаточного статистического материала) в программном комплексе был использован специальный
количественный критерий, отражающий качество сохранности паттерна периодичности [3, 4].
В основе вычислительной технологии лежит модель эволюции тандемного повтора путём последовательных дупликаций смежных копий
текстового паттерна. Для верификации найденных участков скрытой периодичности, в общем случае, используются две характеристики − значение
уровня сохранности паттерна периодичности pl (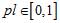 ) и значение
параметра HL, показывающего значимое отклонение от однородности (на уровне α = 10-6) на тестируемом
периоде. Максимальное значение параметра pl указывает истинную длину периода при условии, что параметр HL
гарантирует неоднородность нуклеотидной последовательности на таком периоде при количестве копий больше 20. При количестве копий,
не превышающем 20, используется только одна характеристика − значение
уровня сохранности паттерна периодичности pl. Оно не должно быть меньше 0.625.
) и значение
параметра HL, показывающего значимое отклонение от однородности (на уровне α = 10-6) на тестируемом
периоде. Максимальное значение параметра pl указывает истинную длину периода при условии, что параметр HL
гарантирует неоднородность нуклеотидной последовательности на таком периоде при количестве копий больше 20. При количестве копий,
не превышающем 20, используется только одна характеристика − значение
уровня сохранности паттерна периодичности pl. Оно не должно быть меньше 0.625.
Метод подсчета уровня сохранности pl(L) состоит в следующем. Анализируемая строка длины n, состоящая
из букв алфавита A = {a1,…,aK}, разбивается на подстроки
длины L, равной длине тест-периода. Количество подстрок 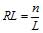 называется
кратностью, а массив подстрок называется L-профилем.
L-профиль позволяет вычислить частоту
называется
кратностью, а массив подстрок называется L-профилем.
L-профиль позволяет вычислить частоту 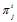 встречаемости
i-той буквы алфавита A в j-той позиции (j-том столбце) профиля для i = 1,…, K и
j = 1,…, L. По матрице частот
встречаемости
i-той буквы алфавита A в j-той позиции (j-том столбце) профиля для i = 1,…, K и
j = 1,…, L. По матрице частот 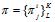 вычисляется значение уровня
сохранности паттерна pl для значения тест-периода L:
вычисляется значение уровня
сохранности паттерна pl для значения тест-периода L:
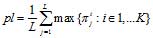
и спектрально-статистического параметра HL:
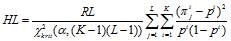 ,
,
здесь pi − частота встречаемости i-той буквы алфавита A во всей анализируемой строке.
Хромосомная ДНК многократно сканируется скользящим окном, длина окна равна
удвоенной длине тест-периода, а шаг смещения окна является переменной величиной, зависящей от длины тест-периода. Количество
проходов такого сканирования зависит от диапазона длин тест-периодов, заданного пользователем (по умолчанию используется
диапазон от 2 до
10 н.п.). Указанные значения параметров выбраны для того, чтобы обеспечить разумное время счета для последовательности,
заданной пользователем. При увеличении диапазона длин тест-периодов время работы процедуры поиска существенно возрастает.
Если уровень сохранности двух одинаковых по длине смежных участков в окне оказывается не меньше 0.875 (т.е. эти участки
отличаются между собой не более, чем в четверти позиций), мы считаем эти участки размытыми повторами с кратностью 2.
Затем перекрывающиеся участки с одной и той же длиной тест-периода анализирутся с целью формирования из них путем слияния
одного участка, характеризующего периодичность более высокой кратности на участке хромосомы, покрытой набором участков
попарного сходства. Специальные усилия предпринимаются для очистки левой и правой границ участков от позиций, не имеющих
отношения к паттерну периодичности. Технология слияний и удалений участков повторяется многократно с различными
параметрами и условиями.
